2 Scaling Laws
2.1 Train-Time Scaling
Many researchers have asked the question: as you scale the three ingredients of deep learning—model size, dataset size, and compute—how does performance change? Following on from this, given a fixed budget for training a model, how much should you scale each ingredient to be “compute-optimal”? Here we investigate these findings, what the implications are and current open questions. Most importantly, I hope to convince you why you should spend significant effort on scaling up your deep learning projects, and how to do so effectively.
Given these findings, we have seen an unprecedented increase in the scale of frontier models (see Figure 2.1).

If you read a book every day for 70 years, that is roughly \(25{,}000\) books. At \({\sim}100{,}000\) tokens per book, that is \(\approx 2.5 \times 10^9\) tokens in a lifetime. GPT-4 was trained on \(5 \times 10^{12}\) tokens—about 2,000 human lifetimes of non-stop reading.
Grok 3 was trained using \(\approx 6 \times 10^{26}\) FLOPs—roughly 1,000 moles of floating-point operations. If you were given one atom of gold for every FLOP, you would have \(1{,}000 \times 197\text{ g} \approx 200\text{ kg}\) of gold.
Kaplan et al. [2] showed that cross-entropy loss \(L\) on language modelling tasks (next token prediction) follows power laws in each of the three scaling dimensions:
\[ L(x) = \left(\frac{x_c}{x}\right)^{\!\alpha_x} \tag{2.1}\]
where \(x\) is one of: number of parameters \(P\), dataset size \(D\), or compute budget \(C\), and \(x_c\), \(\alpha_x\) are empirically fitted constants. Crucially, these power laws hold over many orders of magnitude.

These scaling laws imply that performance improves smoothly and predictably with scale. There are no sudden “phase transitions” in the loss curves—larger models, more data, and more compute reliably produce better models. This had two important consequences for the industry: first, scaling laws gave companies a clear engineering objective—improving performance reduced to spending more compute; and second, companies balanced the three ingredients (parameters, data, and compute) according to the findings in [2].
Hoffmann et al. [3] (the “Chinchilla” paper) identified an issue in the Kaplan experimental setup: all runs used a fixed learning-rate schedule, one designed for \(\sim\) 130B tokens. This made training on fewer tokens look less effective for smaller models than it really is, biasing the compute-optimal recommendation towards bigger models trained on relatively fewer tokens. As a consequence, the field had systematically trained models that were too large on too little data—GPT-3 (175B parameters), for example, was trained on only 300B tokens. This serves as a cautionary tale: empirical scaling laws are only as reliable as the experimental design behind them.

The corrected compute-optimal recipe from Figure 2.3 allocates compute roughly equally between model size and data:
\[ D^* \approx 20 \times P^*. \]
That is, the optimal number of training tokens is approximately 20 times the number of parameters. The Chinchilla-optimal allocation for GPT-3’s compute budget would have been a 70B-parameter model trained on 1.4T tokens.
These scaling laws also extend beyond language. Henighan et al. [5] showed that the same power-law relationships hold for autoregressive generative modelling across images, video, mathematical problem solving, and multimodal domains. Muennighoff et al. [6] extend the analysis to the data-constrained regime, showing that when unique data is exhausted and tokens must be repeated across epochs, returns degrade predictably—up to a point where additional compute is better spent on more parameters than on further repetitions.
2.1.1 Scaling laws in 2026
Recently there has been some skepticism of scaling. These revolve around rumours of diminishing returns, bottlenecked resources and other algorithmic improvements that might make scaling less important.
Rumours have emerged suggesting that the next generation of frontier models was delivering smaller performance jumps than previous generations. OpenAI’s GPT-4.5—originally intended to be GPT-5—was reportedly only a moderate improvement over GPT-4; some researchers at the company believed it was not reliably better than its predecessor on certain tasks, despite a massive increase in training cost [7]. This fuelled a broader narrative that pre-training scaling had hit a wall. Prominent figures added to the discourse: Sutskever declared at NeurIPS 2024 that “pre-training as we know it will unquestionably end” [8].
Even if scaling works, we may be bottlenecked in our ability to do it. Sevilla et al. [9] project that training runs of \(2 \times 10^{29}\) FLOPs will be feasible by 2030—comparable to the jump from GPT-2 to GPT-4—but identify power consumption and chip manufacturing as the binding constraints. Single data centres of 1–5 GW are plausible, though proposals for geographically distributed training (and even orbital data centres [10]) highlight how extreme the engineering is becoming.
There are also strong reasons to believe algorithmic improvements now matter more than raw scale. Hooker [11] argues that our understanding of why models need so many parameters remains remarkably shallow: we can prune the vast majority of weights after training, with little performance loss, yet those same weights appear essential during training (more on this later!). If we understood this gap, far more efficient training algorithms might follow (humans can perform impressive cognitive tasks fuelled by nothing more than a chocolate bar). This is compatible with Sutton’s Bitter Lesson [4], which advocates scaling compute when you can, but does not claim it is always the most efficient path.
The more nuanced reading is that the easiest scaling wins—simply making models bigger on web-crawled data—are indeed exhausted, but progress has shifted to data quality, post-training techniques, and inference-time compute scaling (see Section 2.2). This is good news for computer scientists: first, the practical scaling techniques introduced in the remainder of this chapter will let you operate at the frontier of what is possible with your available compute; and second, we are back in a world where scientific breakthroughs in algorithms and data quality can matter as much as sheer scale.
2.2 Inference-Time Scaling
While the scaling laws above focus on training compute, a recent paradigm shift has emerged: scaling compute at inference time can also dramatically improve performance. Traditional scaling invests compute during training: more FLOPs, more data, larger models. Inference-time scaling instead invests additional compute when generating each answer, by having the model “think longer” before producing a response.
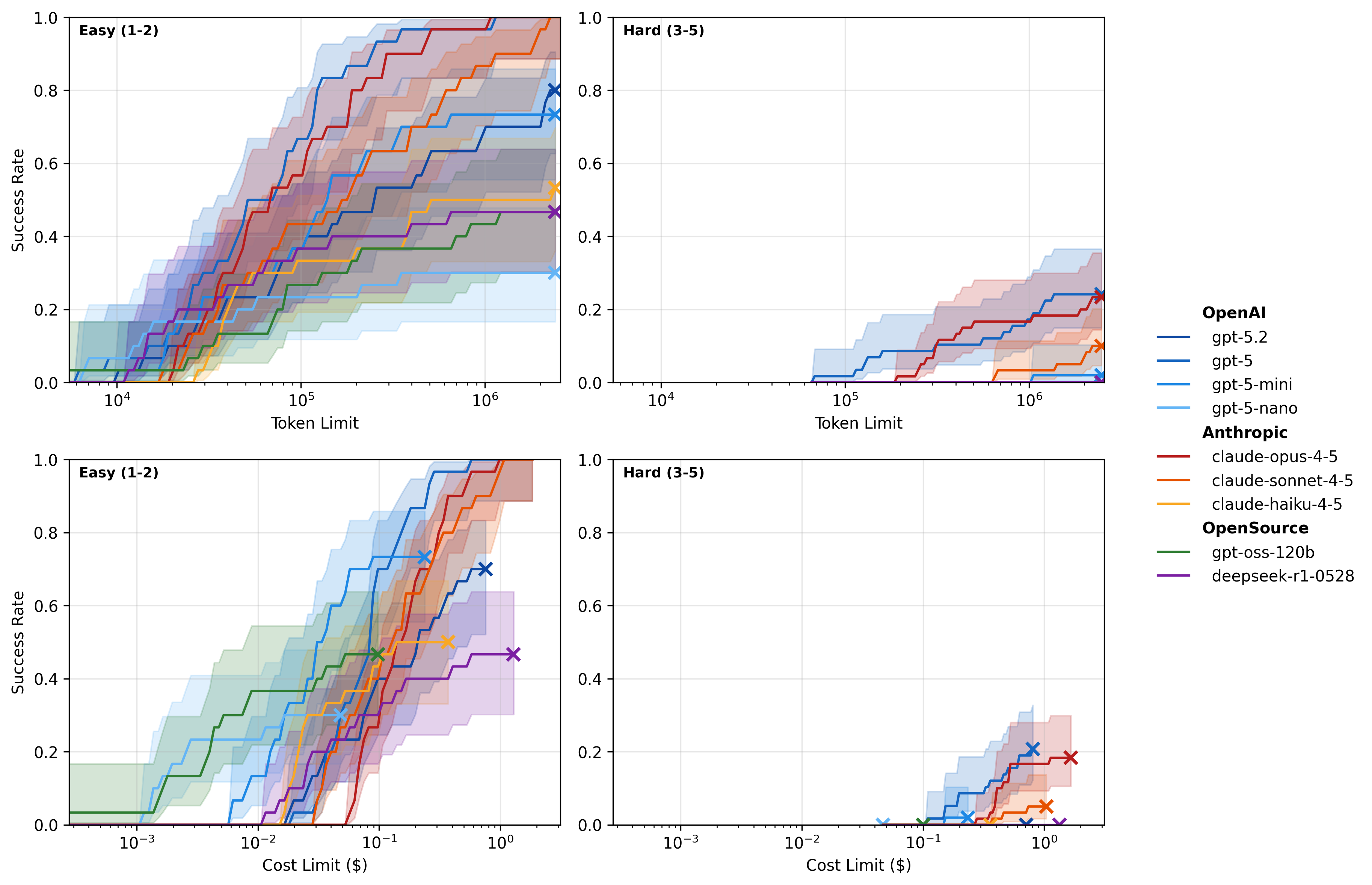
One of the simplest forms of inference-time scaling is repeated sampling: generate \(k\) independent solutions. Brown et al. [12] studied this approach systematically and found that pass@\(k\) scales log-linearly with the number of samples \(k\). As shown in Figure 2.4, even a weaker model can surpass the single-attempt state of the art by simply generating more candidate solutions.
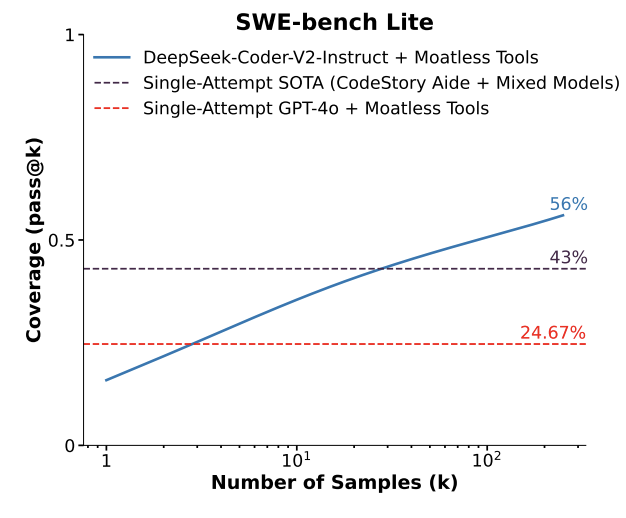
This approach is particularly effective in verifiable domains—settings where candidate solutions can be checked automatically— or multiple attempts are cheap. Software engineering is a natural fit: if you can write unit tests for a task, you can generate many candidate patches and keep the one that passes. Mathematical proof is another: a proof can be mechanically verified even if finding it is hard. More broadly, any domain with a cheap verification oracle turns repeated sampling into a reliable strategy for trading compute for correctness.
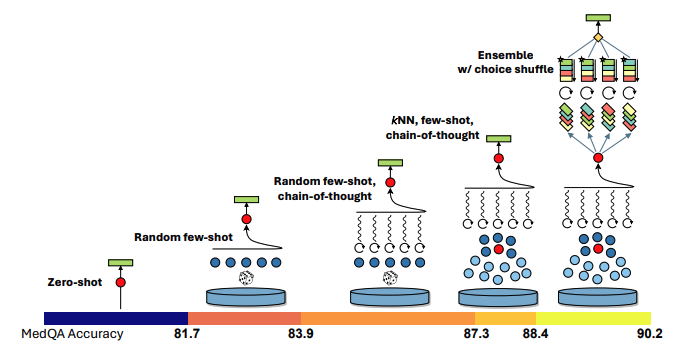
More sophisticated approaches build on this basic idea by adding structure to how samples are generated, filtered, and combined. Nori et al. [13] showed that generalist models with no medical fine-tuning could outperform specialist medical models when using these methods demonstrating that intelligent orchestration of parallel samples can extract substantially more from a model than naive repeated sampling alone. Samadi et al. [14] scaled test-time compute to achieve IOI gold-medal performance with open-weight models. Their framework generates a large pool of candidate solutions, clusters them by behavioural similarity, ranks the clusters, and submits solutions via a round-robin strategy—performance scaling consistently with available compute. These results suggest that the ceiling for parallel inference-time scaling is far higher than simple pass@\(k\) curves might imply, provided the selection and aggregation mechanisms are sufficiently sophisticated.
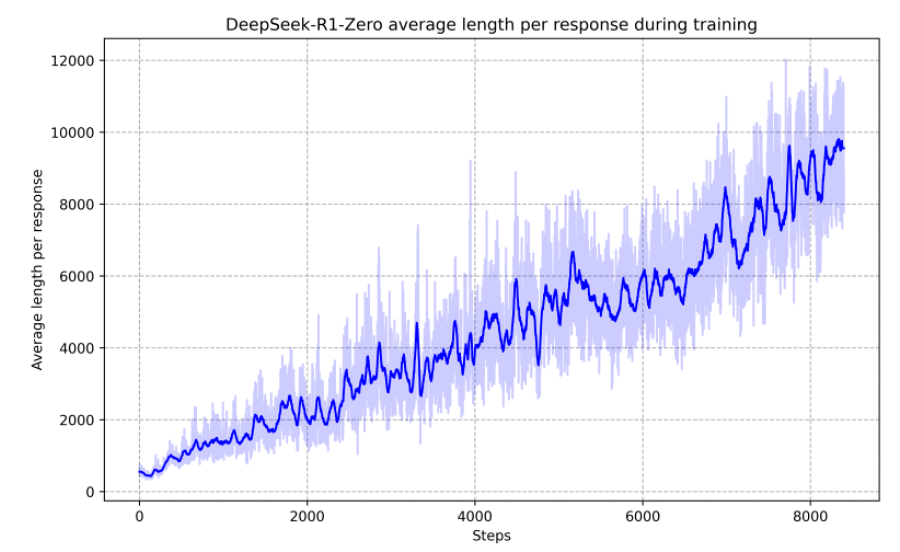
A key breakthrough in inference-time scaling is the use of reinforcement learning to train models to reason. DeepSeek-R1 [15] demonstrated that reasoning capabilities can emerge purely from RL, without supervised fine-tuning on reasoning traces. Using Group Relative Policy Optimization (GRPO), the model learns to decompose problems, verify intermediate steps, and explore alternative solution paths—all from a simple reward signal. A striking side effect of this training is that the model spontaneously learns to think longer on harder problems: as RL training progresses, average response length increases steadily (see margin figure), indicating the model is learning to allocate more inference-time compute where it is needed.
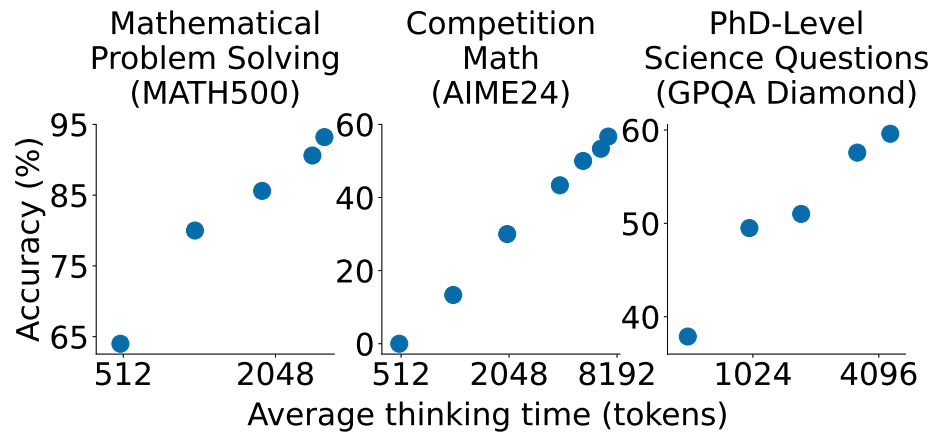
Muennighoff et al. [16] showed this relationship explicitly with s1, a simple test-time scaling approach that controls inference-time compute through a “budget forcing” mechanism adjusting the length of the model’s chain of thought. As shown in Figure 2.5, accuracy scales consistently with thinking time across mathematical and scientific reasoning benchmarks. The key insight is that allowing models to generate extended chains of reasoning—sometimes thousands of tokens of intermediate “thinking”—can solve problems that are beyond the reach of direct generation.
This scaling relationship extends beyond pure reasoning to agentic tasks. In a paper that I hope to release this week (code), we evaluated frontier models on container sandbox-escape challenges—tasks requiring multi-step vulnerability discovery and exploitation—and found that success rate scales log-linearly with the inference-time token budget (Figure 2.6). These results suggest that sequential inference-time scaling is a general phenomenon: whether the task is mathematical reasoning or autonomous multi-step problem solving, allowing models to “think longer” reliably improves performance. These findings motivate our inference optimisation section.